
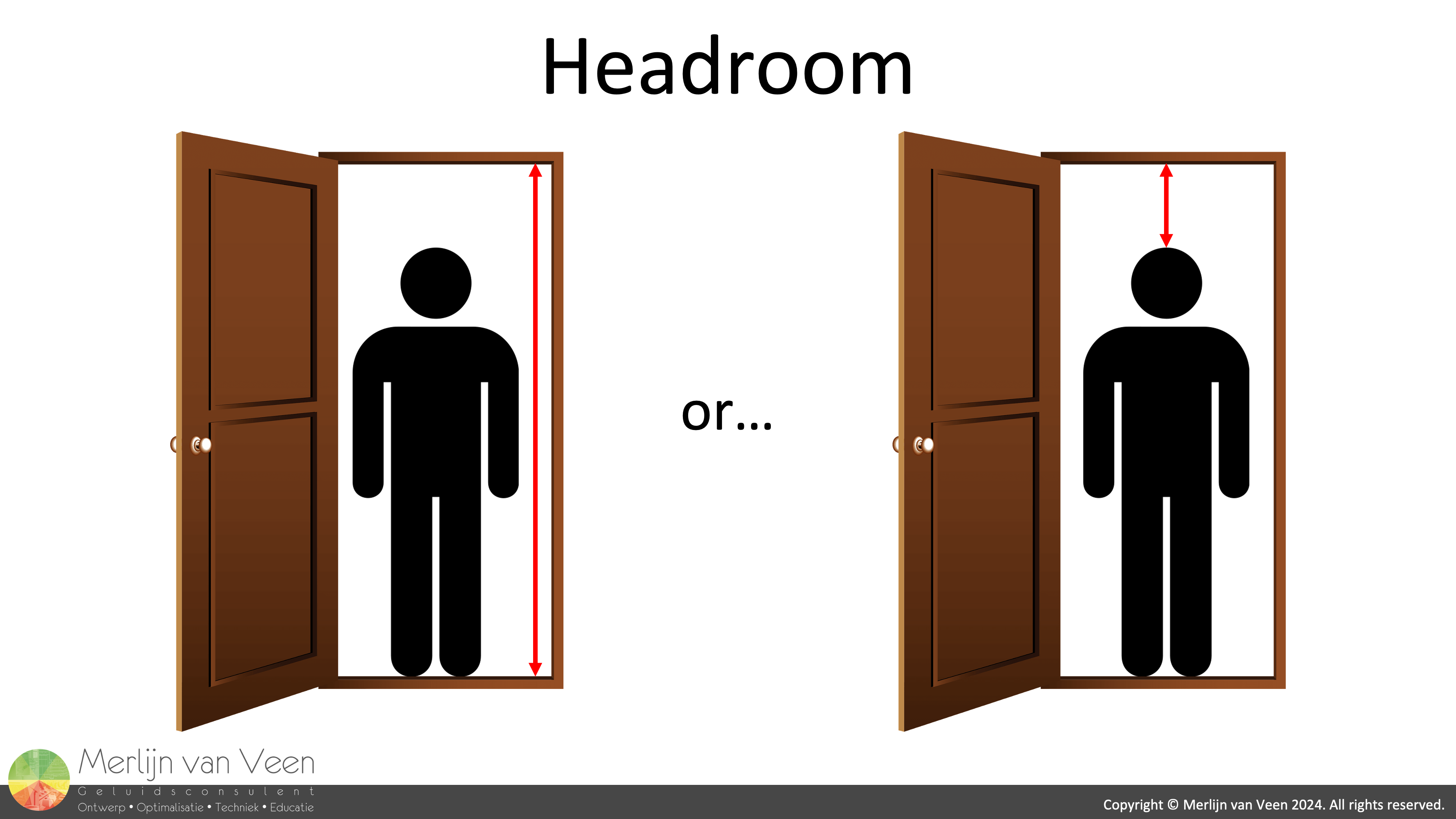
 Figure 1Our industry is notorious for its ambivalence regarding consensus on definitions, and the definition of headroom is no exception. A recent Facebook poll revealed a 20/80 divide between the two most common definitions.
Figure 1Our industry is notorious for its ambivalence regarding consensus on definitions, and the definition of headroom is no exception. A recent Facebook poll revealed a 20/80 divide between the two most common definitions.
Headroom's ambiguity may stem from a paradigm shift in audio technology. And the solution could be straightforward. Where simply adopting a new term might end the status quo.
"After 50+ years of live sound reinforcement, we agree on one thing:
reversing polarity means swapping plus and minus."
— Bob "6o6" McCarthy —
The poll offered two definitions to choose from:
- How far signal peaks can stray from nominal before the onset of non‑linear behavior
- The safety clearance between signal peaks and the onset of non‑linear behavior
Boy, did that spark some contentious debate, including concerns that terms like "stray" and "safety" might bias the outcome.
So let us explore why I carefully choose this wording, by dissecting key words. And discover why the first definition is signal‑content‑agnostic and the second one is not. But first:
Plain English
For starters — even in plain English — there is no consensus on the meaning of the word headroom.
"vertical space in which to stand, sit, or move"
— Merriam‑Webster dictionary (American English) —
"space or clearance overhead"
— Oxford dictionary (Britisch English) —
I have come to think of the former as "foot room" whereas the latter is much more intuitive (Figure 1). After all, the clue is in the fricking name!
A casual search (by no means comprehensive) for the definition of headroom led to interesting observations.
Paper trail
For starters, the online IEC Electropedia — which promotes the global unification of terminology in the fields of electrotechnology, electronics, and telecommunications — does not feature and entry on headroom...
Bearing in mind that, the Electropedia is the world's most comprehensive online terminology database on “electrotechnology”. And contains all the terms and definitions in the International Electrotechnical Vocabulary (or IEV) with more than 22 000 terminological entries. Most of which, if not all, are used in leading IEC Standards.
Well maybe we got unlucky on the first try. So let us consult another respected source: the online AES Pro Audio Reference (or PAR).
"A term related to dynamic range, used to express in dB,
the level between the typical operating level and
the maximum operating level (onset of clipping)."
— AES Pro Audio Reference —
And also some literature as well as more online resources.
"... refers to the amount by which the signal-handling capabilities
of an audio system can exceed a designated nominal level."
— Wikipedia —
"Every recording medium has an ‘Optimum’ recording level
where its specifications shine. We call everything above this point, ‘Headroom’"
— "Mixing with your mind" by Stavrou —
"Traditionally, the difference between average level
and clip point has been call the headroom."
— "Audio Mastering" by Bob Katz —
"The difference between peak and average level
is referred to as the system headroom"
— "Handbook for Sound Engineers" by Ballou —
"Overload reserve. The amount of signal above nominal level
that can be permitted before overloading arises
with distortion as a consequence."
— "Audio Metering" by Brixen and DPA Microphone Dictionary —
"It is defined as the region between
the nominal operating level (0VU) and the clipping point."
— Sound on Sound Glossary —
"Headroom is defined as the available level
above the nominal level before clipping."
— iZotope —
Note that all of these quoted definitions align best with the first option in my poll, that only received 20% of the votes. And how all of these definitions solely consider — gear and levels — completely independent of signal‑content.
However, there are also some colloquialisms being mixed up indiscriminately. Most notably, nominal, average, and typical (operating) level. So let us try to sort that first, while staging some additional terms as well.
Terms and definitions
| Term | Definition |
| SUT | System Under Test A device or collection of devices, including media |
| Level | The — mean (RMS) — value during a time interval and generally expressed in decibels |
| Peak Level | The maximum — instantaneous — level |
| Crest Factor | The peak‑to‑average ratio of a — signal — oftentimes expressed in decibels |
| Nominal Level | Typical or average operating level and — unless stated otherwise — 0 VU or +4 dBu or -14 dBFS (EBU) or -20 dBFS (SMPTE) |
| Clipping | A form of waveform distortion that occurs when a SUT is overdriven and attempts to handle an amplitude beyond its maximum capability |
There are several important distinctions: first — unless stated explicitly — level always assumes an average (or mean) as opposed to a peak. And secondly: nominal level is signal‑agnostic, and always relates to the — system under test — as opposed to signal‑content. Whereas crest factor is a property of the signal and not the gear.
As for rating a SUT's maximum level capability, or clip (or clipping) point, distortion seems to be a key factor. But not all distortions are necessarily bad.
Soft and hard clipping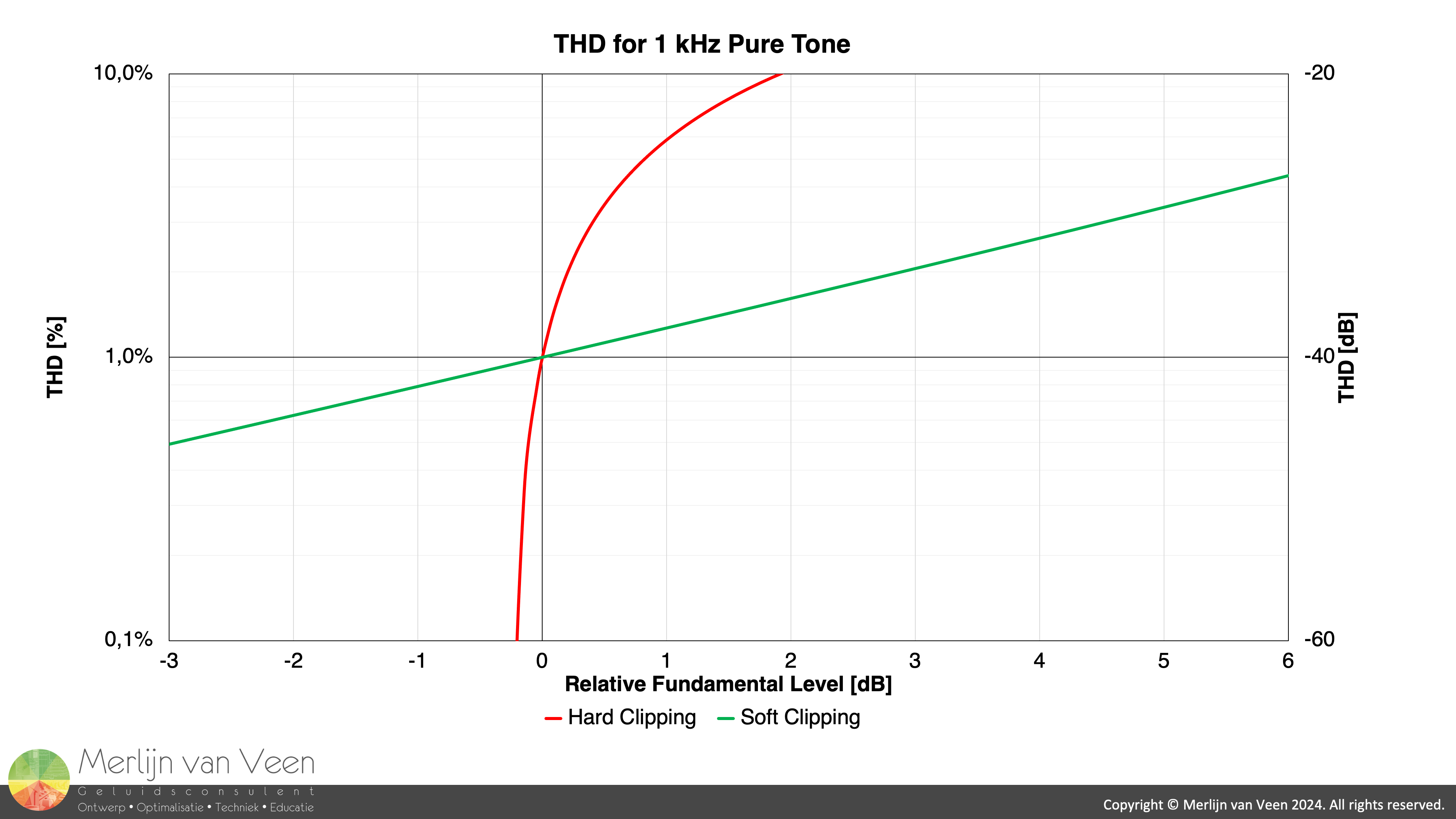 Figure 2Figure 2 compares an example of soft clipping versus hard clipping of a 1 kHz sine wave. The chart has been staged such that both clipping types reach 1% THD for the same — relative — fundamental level.
Figure 2Figure 2 compares an example of soft clipping versus hard clipping of a 1 kHz sine wave. The chart has been staged such that both clipping types reach 1% THD for the same — relative — fundamental level.
Notice that, the soft clipping — example — reminiscent of analog technology, rises very gradually as the fundamental level rises. Whereas distortion by hard clipping, associated with digital audio, jumps up out of nowhere, once the tipping point — 0 dBFS — is reached, and rises dramatically.
Hard clipping — over the course of little over 2 dB — rockets to a whopping 10% THD. While soft clipping's fundamental level can grow for another 6 dB, and still reaches only 5% THD.
Not to mention that — for analog technology — the composition of the harmonic distortion products, and the balance between even and odd harmonics, oftentimes adds a desirable signature sound. That gave rise to descriptive attributes such as "warmth" and "vintage".
Which may explain why engineers — before the advent of digital audio — were less peak‑phobic than today's engineers that dread hard clipping due to its unforgiving and highly distorted and dissonant sound. That can be painful on the ears.
Dynamic range and SNR mattered more
In the analog era, engineers worried more about signal‑to‑noise ratios, and their SUT's "rather limited" total dynamic range. That is, the range between the SUT's noise floor — not to be mistaken for its nominal operating level — and its clipping point. And chose their nominal operating levels to maximize SNR without being overly peak‑centric.
To paraphrase Michael Paul Stavrou: "Every SUT has an ‘Optimum’ — level — where its specifications shine." Which may explain why early VU meters' ballistics were optimized for monitoring loudness, at the expense of being too inert to read fleeting signal peaks.
Simply because — contrary to digital audio — signal peaks were far more less likely to get brutally decapitated or "flat‐topped", but saturated in stead. In a much more forgiving and oftentimes desirable fashion.
Be it may: first, even though moderate distortion can be desirable at times — albeit highly subjective — you cannot standardize an industry definition with moving goalposts. And secondly, regardless of how pleasant it sounds, it is nevertheless non‑linear behavior.
Rating maximum level
Historically1 — among other methods — to rate maximum levels, and estimate a SUT's ceiling, one passes a pure tone, that is, a clean sine wave without higher harmonics, through the SUT. And raises its level until the invoked harmonic distortion exceeds a predefined threshold of "acceptable" distortion. At AES we call this a stop‑condition.
For microphones, the stop‑condition can be as little as 0,5%. Which is generally accepted to be the lowest threshold for noticing distortion. Whereas, for analog reel‒to‑reel magnetic tape it tends to be 3%.
Regardless — for analog technology — the ceiling tends to be softer, and maximum levels can be considered penultimate ratings. Where one can go higher — within reason — in exchange for more distortion (Figure 2). Not for digital audio where the ceiling is hard. Very hard.
So now we finally have all the ingredients to dissect the first definition in my poll (the traditional and oldest of the two).
Definition One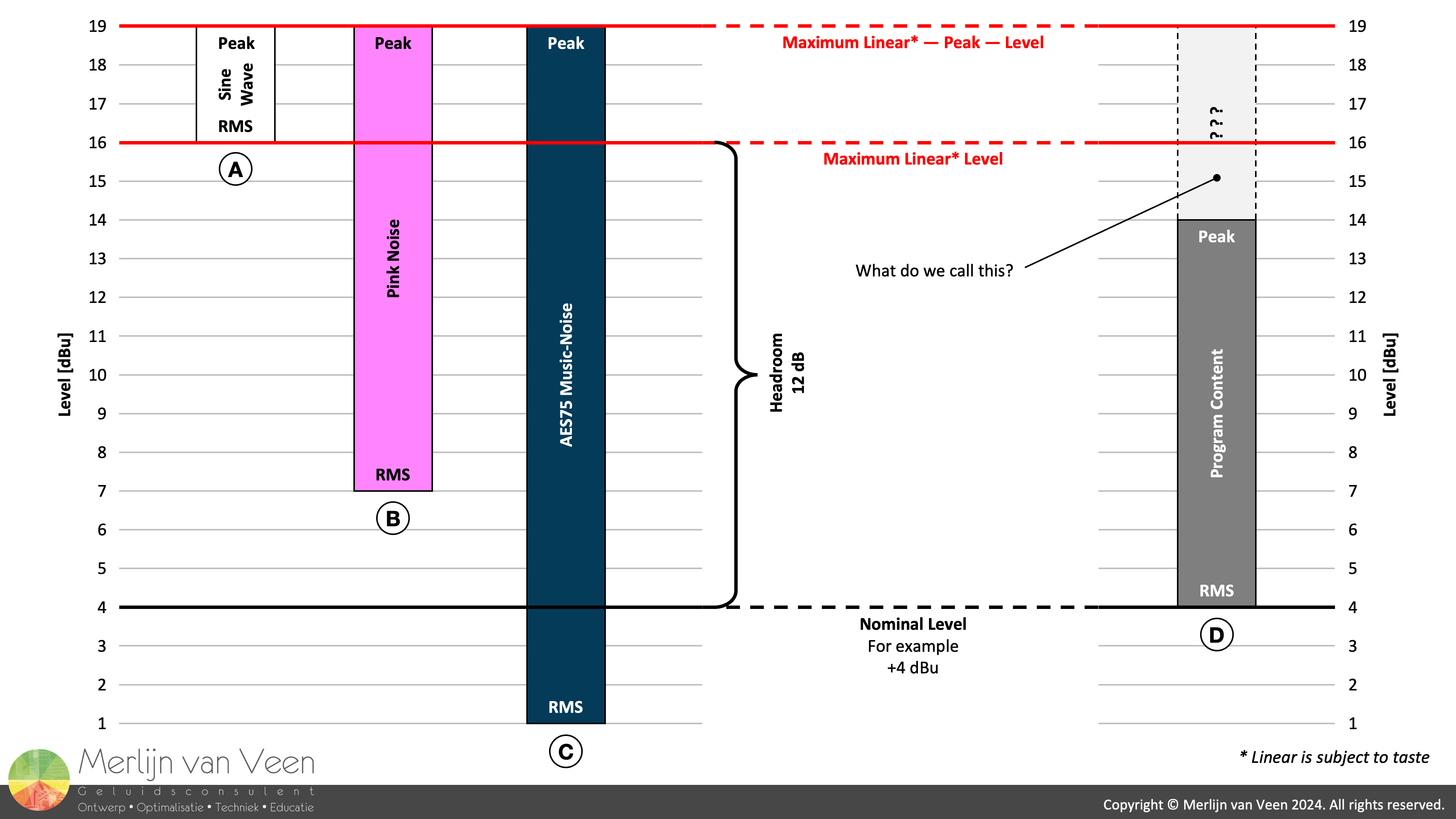 Figure 3Figure 3 shows an imaginary level diagram for a SUT whose "designated" (Wikipedia definition) nominal operating level is +4 dBu (0 VU). Where scenario "A" represents the maximum for passing an "undistorted" sine wave. Whose (RMS) level denotes the SUT's maximum "linear" level.
Figure 3Figure 3 shows an imaginary level diagram for a SUT whose "designated" (Wikipedia definition) nominal operating level is +4 dBu (0 VU). Where scenario "A" represents the maximum for passing an "undistorted" sine wave. Whose (RMS) level denotes the SUT's maximum "linear" level.
From here, we can derive the traditional headroom value by subtracting +4 dBu (nominal level) from +16 dBu (max level) which yields 12 dB of headroom. However, given the crest factor of the test signal, that is, the sine wave — instantaneous — signal peaks exceed the maximum linear level by another 3 dB.
So indirectly, while being — level — centric (as opposed to peak), the traditional headroom definition (by extension) does convey how far signal peaks can "stray" from nominal before the onset of non‑linear behavior.
The example SUT in Figure 3 can pass content — at nominal level — that is, content whose (RMS) level matches the SUT's nominal level, with instantaneous signal peaks straying by as much as 15 dB.
Now let us look at scenario "B" in Figure 3. This considers a pink noise signal, with 12 dB crest factor, that also utilizes all available headroom. But can be passed louder by 3 dB above nominal while remaining withing the linear range of operation.
Whereas scenario "C" shows AES75 Music‑Noise, whose crest factor is 18 dB, that can only pass under linear conditions when turned down by 3 dB below nominal. Regardless, in all three scenarios (A through C), all available headroom has been utilized since the signals were peak‑normalized.
So we have seen that headroom can be utilized by raising signal level — crest factor permitting — above nominal, or increasing the signal's crest factor without raising its level, or a combination of both.
Now let us look at scenario "D" in Figure 3, where we see a signal passed at nominal level that does not utilize all available headroom. How do we call the "safety clearance" or "reserve" between its instantaneous peaks and our SUT's ceiling?
Bearing in mind that, according to the first traditional definition, the word "headroom" is already taken to describe a property of the SUT itself. So we need another term...
You may be interested in reading that Bob Katz, in his seminal book "Mastering Audio", calls this safety clearance the "cushion". Whether this is the right word remains to be seen. But at least he too acknowledges that we need one more term.
But what if the shoe were on the other foot, and we declare the safety clearance as headroom in stead. This brings us to the second definition of my poll which received 80% of the votes. And is much more intuitive, even in plain English.
Definition Two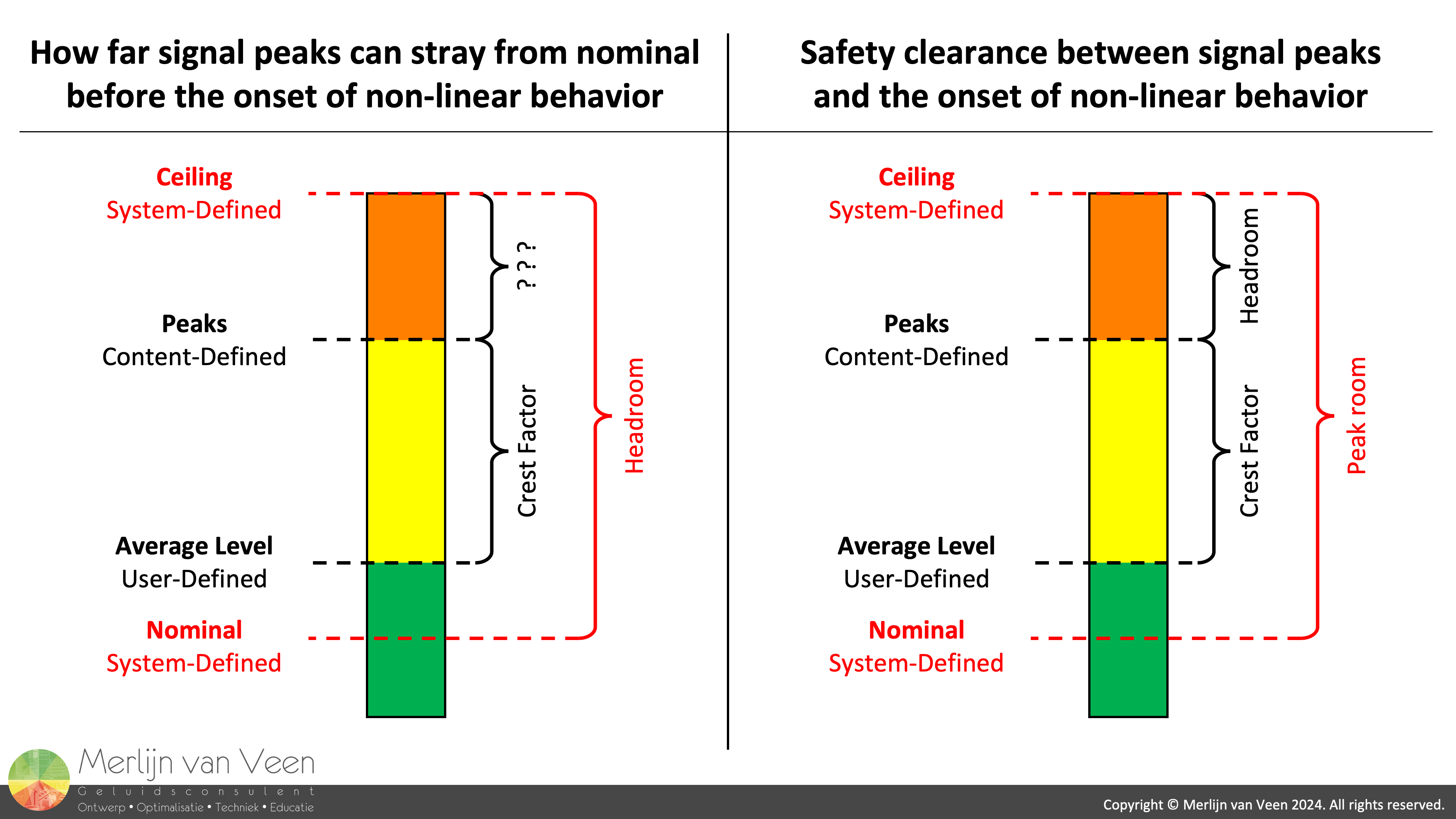 Figure 4Figure 4 shows a graphical illustration of both definitions side by side. The left example shows definition one, where we find ourselves hurting for another term to the describe the remaining safety clearance.
Figure 4Figure 4 shows a graphical illustration of both definitions side by side. The left example shows definition one, where we find ourselves hurting for another term to the describe the remaining safety clearance.
Whereas the right example illustrates the second definition, where we choose to declare the safety clearance headroom in stead. But then we will need a replacement word for the former. Which we will get to in second.
The upside it that we get an unambiguous, relatable, definition that is much more intuitive in today's digital era. That — contrary to analog technology — has triggered everybody's peak‑phobia because of the nature of hard clipping.
The solution: Peak Room
If we give the traditional definition of headroom an aptly upgrade to suit today's audio technology (which the poll suggests has already happened organically). We need a replacement term for its old job description.
The contender term has been around for quite some time, but regrettably fails to gain traction. While the embarrassing ambiguity surrounding headroom — even among industry veterans — continues.
Long time ago, Pat Brown pitched the brilliant term "Peak Room" to replace headroom's old job. And it is a super‑intuitive term to describe this signal‑content‑agnostic property of an SUT.
Peak room perfectly captures the — essence — of the traditional first definition, that is: how far signal — peaks — can stray from a SUT's nominal operating level before the onset of non‑linear behavior.
Imagine a SUT with 20 dB peak room — bearing in mind that nominal is ultimately an opinion (Wikipedia definition) — this informs me that, I can pass a sine wave at nominal with 17 dB of headroom left, pink noise with 8 dB of headroom left, and AES75 Music‑Noise with 2 dB of headroom left.
Notice how headroom has now become a — function of signal content — rather than a property of the SUT. And lets us utilize it accordingly, by — in this example — running the sine wave 17 dB above nominal, pink noise 8 dB above nominal, or AES75 Music‑Noise 2 dB above nominal.
How convenient and easy. Let us try to make it stick this time. And thank you Pat!
1 Disclaimer
Measuring non-linearity using pure tones is just the most basic method. There is a wide variety of other tests that are equally important, especially as systems like amplifiers and loudspeakers grow more complex.